

Content management needs to be core technology
Content management should be core infrastructure, not overhead. Version control and process make content trustworthy without extra work. Read: "Everything Starts Out Looking Like a Toy" #267

Hi, I’m Greg 👋! I write weekly product essays, including system “handshakes”, the expectations for workflow, and the jobs to be done for data. What is Data Operations? was the first post in the series.
This week’s toy: “social credit” is something we think about in the digital world — it’s the Uber rating, number of likes you get on a post, or another abstract thing. Could a social credit rating become more important in regular life? As everything’s becoming digitized, it seems possible and maybe even likely. Edition 267 of this newsletter is here - it’s September 8, 2025.
Thanks for reading! Let me know if there’s a topic you’d like me to cover.
The Big Idea
A short long-form essay about data things
⚙️ Content management needs to be core technology
Content management is not typically the top item on your list of technology to build. The simple reason is that strictly speaking, you don't need to build that technology. It's just files! You can store them on a file system, in Google Docs, in Confluence, in GitHub, or anywhere else you want to store them.
What happens when you want to collaborate on those files with other team members? They want to use the file system they use every day, instead of learning a new one or following a process to keep those files updated.
The dirty secret of content management is that people hate process.
No one wants to follow a template to update an AI prompt, update a help center article, or a tag an internal wiki page. They don't mind updating the content but they don't want to take on extra work on top of the "real work."
That's why most content systems slowly collapse under their own weight. They accumulate outdated docs, duplicate prompts, and abandoned wikis.
But teams want relevant AI responses, just-in-time in-context help, and agent content that shares the right information for today's product. That means that prompts, help center articles, and internal knowledge should be considered infrastructure for your business.
The hidden "job to be done" for content management is to ensure content stays accurate, trustworthy, and useful without adding work that feels like a drag.
The three surfaces of content
It's trendy to think that Prompts are vibe-coded versions of instructions. Now they're production code, tied to a specific eval (and perhaps, to a specific model). When a prompt breaks, your sales motion or support workflow might be immediately impaired. That means Prompts need the same rigor as other releases.
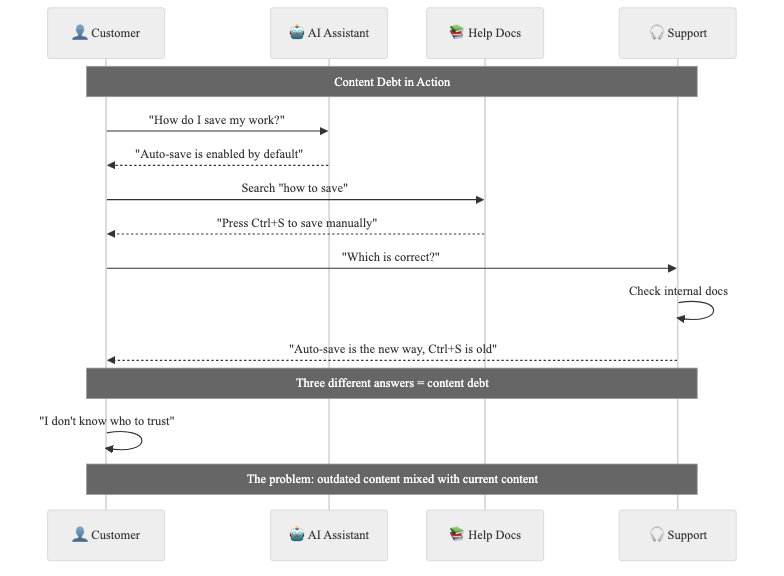
Help center content is another related set of content. It doesn't change that often, until you release a new feature and recognize that customers are following an outdated set of instructions. Cleanup mode involves understanding the content debt that's out there and revising the help center just in time, instead of a cadence of reviewing content regularly and updating on a schedule. Because AI tools are also ingesting this content, it can be a double impact when it's wrong.
Internal knowledge is supposed to help team members handle changes in policy and procedure, and often ends up being the last thing to get updated. When this content is not cleaned up, it represents the documentation of layers of old decisions and is hard to sift for the answer of "what's true today"?
The goal of all of these content formats is the same. As a customer or an internal team member, you need to confirm what's true today. And as a content manager, you need to have an inventory and a cadence for the items that need to be updated on new releases or policy changes.
Sidebar: the library without dates
Maybe it would help to think of this content problem in a different context.
Imagine walking into a massive library. The shelves are full, the catalog is digital, and every book looks pristine. But none of the books have a publication date.
You pick up a medical textbook. Is it from 2023 or 1993? You pull down a policy manual. Is this the version your team agreed on last week, or the one that got rejected six months ago? Without dates and versioning and method to manage the content, the library is a confusing place to visit.
And that's what a lot of content systems at organizations look like today. There is an effort to develop items like prompts, help center articles, and internal docs, and there's much less effort to keep them up to date.
Why versioning matters
Content versioning is a key component to build trust in the content you manage.
The current version drives today’s work
You look for the past version when something breaks or when you need to know the past truth at a certain date
The next version prepares your team for launches and change management.
If you're only tracking one or two of these, it's difficult to manage your org's institutional memory.
Making updates easier without extra work
Getting to the state where you manage past, present, and future content is hard because no one wants another system to manage. Most people won’t follow heavyweight governance, so you have to design the "regular way that we work" to do the process work.
Here are a few concepts to help build process invisibly.
Layered storage
There should be only one clear “current version” of a document. If you don't have automatic version control, reach agreement on when a new version needs to exist. When you change that document, change the name of the file to have the version name. Yes, it's a process, but a lightweight one.
Watch out for: Google Doc updates to old files. You can lock down access to old files, and will need help from IT teams.
Consistency across content objects
Keeping context across multiple objects might be the biggest challenge facing content managers. A product update may touch a prompt, a help center article, and an internal policy. If those don't stay aligned, trust evaporates.
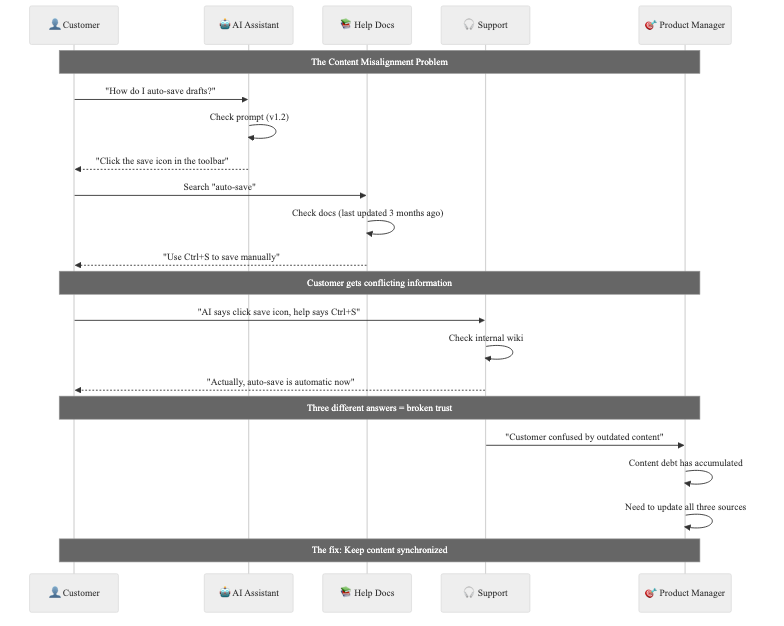
The fix is simple: link related content and make reviewing that linked content part of the launch process. It would be nice if all of these updates could happen "automagically" but the truth is that indexing related content rarely happens automatically unless you're intentional about keeping an index.
AI might be able to help significantly here by building the connective tissue around content quality.
Where tools (and AI) fit
Technology is not a silver bullet. It can help remind us of process but won't replace the humans in every case.
To improve the process, consider where automated features can help
We know that version control gives structure
We also know that people don't always like repetition in and process
AI (or a simple cadence) can help spot stale content, suggest updates, and retrieve a specific content version when asked
These ideas don't replace true content ownership. They make it easier to review it more frequently, but don't establish the principles that make well-managed content useful.
Making process invisible is the goal
If we believe product and operational content is infrastructure, we need to manage it like infrastructure:
Apply version control principles
Standardize ownership and workflows
Let automation and AI carry the burden of structure while humans stay accountable
The lesson is simple: you can’t outsource trust. But you can build systems that make trust easier to maintain.
The goal of content management isn’t to make people love process. We want to bake discipline into the system so humans get the benefit without the burden.
That’s what the right scaffolding offers:
versions tracked without manual logs
content kept fresh without endless checklists
related pieces kept in sync without heroics
The best content management cadences remove friction and increase trust. Let's get started!
What's the takeaway? Content management should be infrastructure, not overhead. Make version control and content freshness automatic so teams get accurate, trustworthy information without extra process work.
Links for Reading and Sharing
These are links that caught my 👀
1/ Is AI the problem, or our questions? - Mike Caulfield explores the problem that happens when AI gives us an authoritative answer that can also be proven wrong. When we look for “vintage photographs”, how do we know what we are looking at is true?
2/ How did the Return key get its name? - On the history of keyboards and the “Return” key. It’s weirder than you think.
3/ On reducing cognitive load - As simple as possible, but no simpler.
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.
The next big thing always starts out being dismissed as a “toy.” - Chris Dixon