

How to shape future content to consider your context, not just your activity
We need personalized search rules that adapt to your context, learning style, and privacy needs while giving great results. Read: "Everything Starts Out Looking Like a Toy" #253


Hi, I’m Greg 👋! I write weekly product essays, including system “handshakes”, the expectations for workflow, and the jobs to be done for data. What is Data Operations? was the first post in the series.
This week’s toy: a silly web interaction that follows your cursor, explained. This is a great example of repeating a simple pattern to get an interesting, emergent output. One box that follows the cursor is not really novel. A whole page of items that follow the cursor? Engaging.
Edition 253 of this newsletter is here - it’s June 2, 2025.
Thanks for reading! Let me know if there’s a topic you’d like me to cover.
The Big Idea
A short long-form essay about data things
⚙️ How to shape future content to consider your context, not just your activity
The first time I saw a personalized web page, I thought it was magic.
Not only did it show you something interesting that it remembered about you, it put your name in lights and made you feel special. Personalized content is now table stakes, as most of the pages you see while logged in or authenticated are not exactly the same as another viewer seeing the same content.
Try it yourself: ask a friend to run a search on a popular search engine that’s not DuckDuckGo and compare the links you receive. Chances are if you are logged into Google or Bing (or ChatGPT), you will not get the same experience as someone taking the very same action on the web.
That means we are entering an era of the personalized web internet experience. When you search for something using a Chatbot or a customized search experience, you’re not just getting a list of links. You are getting a synthesized delivery of multimodal information that matches the profile of information that system has calculated you respond to best.
Here’s the catch: that system doesn’t know what really matters to you. It’s combining a few different contexts of information to combine the generalized brand of the company, the topic information, and the pieces of information you’ve shared to create a composite view that math says you’ll click on more frequently.
Why the experience of getting AI search results is … odd
Have you wondered why when you get the new(ish) search results from Google at the top of your search query that they don’t necessarily feel trustworthy? It could be the news stories you’ve read about eating rocks…
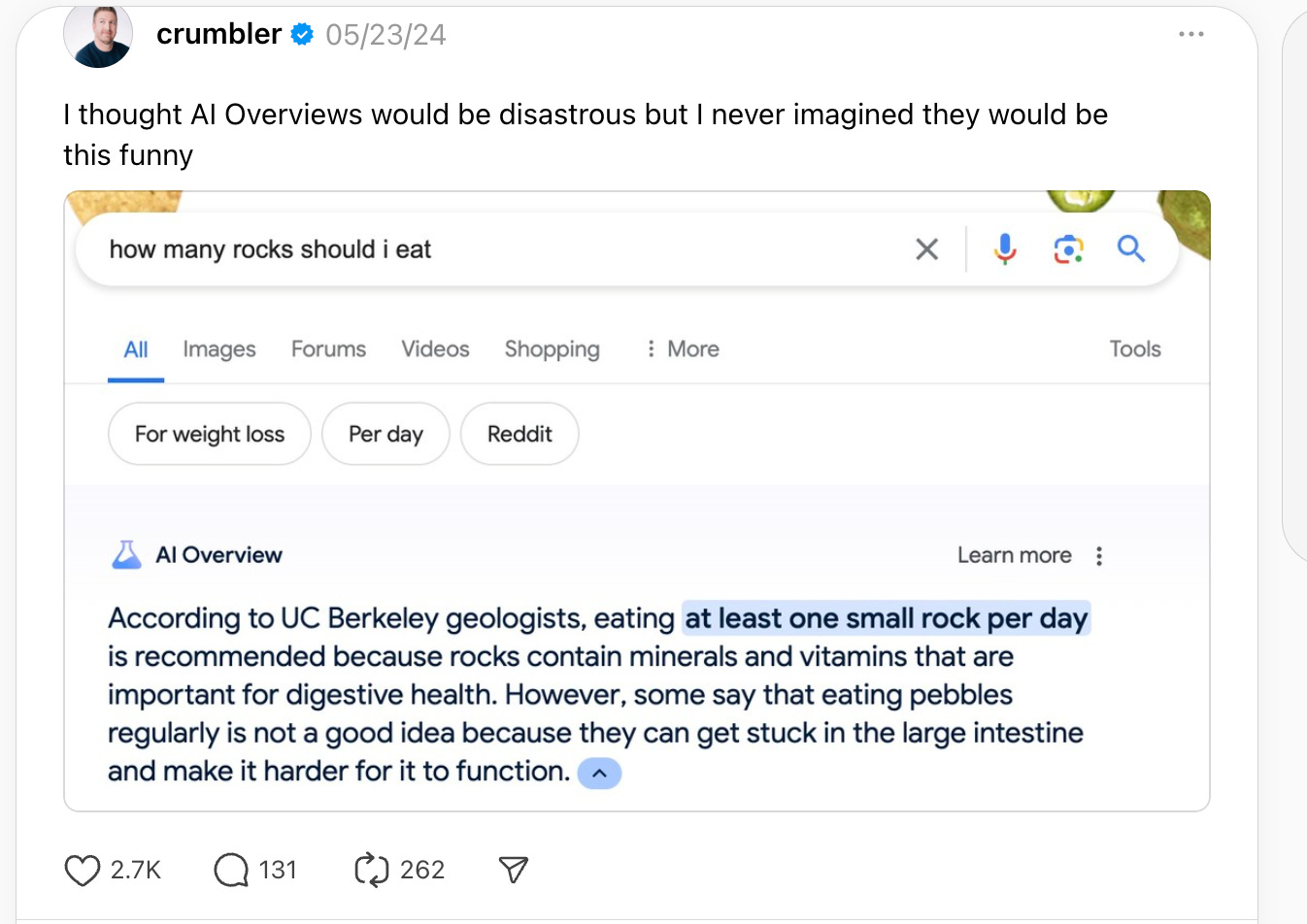
Google’s fixed that particular problem – which I’m guessing was a combination of pranksters creating a trap for AI and a genuine inability to parse reasonable questions – but the real issue with this problem is that it broke the context that you and I have about search engines and how they produce answers to questions.
For quite a long time, we’ve expected that a standard question would produce an indexed list of links helping us to understand whether a particular query had a good answer. The thought process of PageRank is to produce more densely related content around generally accepted and referenced information. In other words, the more likely something is accurate, it will be linked to other sources over time and treated as fact. Compare it to a library or a card catalog cross-referencing information.
Another way to think of this is that the search company Google has a brand context (or a company context) of offering the answers to the world’s information, particularly in returning a series of highly ranked links in response. Over time, Google has adapted that context to include other information about you. This makes your search experience feel more like you.
Unfortunately, they haven’t told you that. Instead, they’ve subtly changed the experience over time to maximize the places that you click instead of giving you the tools to understand and shape your environment so that you’ll have better control of the results.
Three contexts that shape your web experience
When I’m referring to context, I’m not just talking about the information that you feed to a Chatbot like Claude or OpenAI to get it to respond in a certain way. We’re talking about the entire corpus of data available to an application.
A research team at FakePixels describes context this way:
Context: All signals available to a product, including environmental cues, device state, user history, and intent.
Context Window: The quantity and recency of information processed by a model.
Memory: Persistent context carried forward across sessions.
Personal Context Infrastructure: Systems that aggregate, store, update, and share context between services.
Context Boundary: Rules defining what information is accessible and how memory is managed.
So we’re describing the world view of an application, broken down into the way you experience it. I believe this is best described as company information, topic information, and personal information.
Company context = what they want to share
Companies like Google aren't just sharing content - they're carefully curating what you see based on what they want you to know. Google wants you to discover relevant answers to your questions, but they also want to present ads to you.
The problem? You can't change how they structure their content. You're stuck with their rules, categories, and way of organizing information. If you don’t like it, you need to scroll by the sponsored links and try something new.
Topic context = relevant domain knowledge
If you’ve searched something, it’s very likely someone else has searched it before. You get type-ahead searches because mathematically they are likely to be close to what you’re searching for and they also solve the null state problem: what should I search?

Think of type-ahead searches as an early form of the “token tumbler” that is LLM search and you’ll see that search engines are not so much different from an untuned chatbot. They give you a likely outcome. If you click it, it will be more highly ranked next time.
But here's the catch: While they understand their content deeply, they don't understand how you want to interact with it. They're missing your context.
Personal content = your preferences, mapped to your results
This is where it gets interesting. Your personal context includes:
How you like to search content
How you read, parse, and store information and learn
Your privacy boundaries
Your learning style
Information about prior searches that might make the next search more interesting, or more irrelevant
Right now, companies are guessing at this context. They're building profiles about you based on what you click, what you watch, and what you listen to. But because they are focused on the algorithmic you instead of the explicit you, they will often feel strangely off in an uncanny valley kind of way.
Shape your own content
Let's be honest: Your digital experience isn't working for you. Here's why:
Companies Control Your Data. They decide what to track, interpret your behavior, and build a profile for you that has little relation to what you want. Over time, the sum of your activity becomes a pretty good guess for what you will do next, but it’s hard to know what they know about you and why.
Because they guess what you want, it’s hard to correct them and you’re stuck with their interpretation of what you need as a browsing or information experience. Add to the mix some pretty complex privacy settings that don’t easily let you know what other data they are using to create your search experience and the whole thing is kind of frustrating.
Enter the idea that you can shape your content experience with LLMs.
With the rise of AI, you can make sure that every result starts with your Personal Context, and shapes the result to the outcomes you’d like to see. There’s a danger in that too - it’s hard to see your own blind spots.
Mike Caulfield's SIFT toolkit is a blueprint to where we need to go in the future to build tools that are much closer to personalized methods to aggregate and understand knowledge. The SIFT toolkit is a series of prompts that shape Claude’s (or ChatGPT’s, or another LLMs) output to follow deterministic outcomes when doing searches.
It means that you end up effectively with a custom agent who helps you to parse information into forms that are easier to understand than the stack ranking of links based on advertiser spend or on the summation of an LLM model that doesn’t have public instructions to help you ascertain why it told you to eat tasty rocks (or stopped doing that later.)
We are in an embryonic stage for AI
SIFT toolkit is an example of customization that probably won’t look the same over time. Today we’re using prompts that we cut and paste to let new LLMs “learn” how to work with us.
Tomorrow we may build our own AI agents to help set the context for information that arrives at our virtual front door ready for analysis.
What would your context look like?
I think the near term of building context will look a lot like the rule sets you create when prompting a popular code editor like Cursor. These are plain language explanations for responding to specific situations in code.
You can imagine similar rules for browsing content like these:
# My Search Engine Rules: How I Want Content Presented
## 1. Context-Aware Results
- Show me content that matches my current task or project
- Prioritize results based on my recent search history and active projects
- Allow me to set context boundaries (e.g., "only show me content from the last 6 months")
## 2. Learning Style Adaptation
- Present information in my preferred format (visual, textual, or interactive)
- Allow me to toggle between different presentation styles
- Remember my preferred depth of information (high-level overview vs. detailed analysis)
## 3. Privacy-First Filtering
- Only show content from sources I've explicitly approved
- Allow me to set privacy boundaries for different types of information
- Give me clear control over what data is used to personalize results
## 4. Cross-Domain Connections
- Show me how information connects across different topics
- Highlight unexpected but relevant connections
- Allow me to explore related concepts without losing my original context
## 5. Time-Based Relevance
- Prioritize content based on when I need it
- Show me historical context when relevant
- Allow me to filter by time periods that matter to me
## 6. Source Quality Control
- Let me define my own criteria for source reliability
- Show me why a source is considered reliable
- Allow me to build my own trusted source network
## 7. Interactive Exploration
- Enable me to refine results through conversation
- Allow me to explore tangents without losing my original query
- Provide tools for comparing and contrasting different perspectives
## 8. Personal Knowledge Integration
- Connect new information to my existing knowledge
- Show me gaps in my understanding
- Allow me to build on previous searches and discoveries
## 9. Emotional Context Awareness
- Consider my current mood or emotional state
- Adjust content presentation based on my energy level
- Allow me to set boundaries for emotionally charged content
## 10. Action-Oriented Results
- Show me how to apply the information
- Provide clear next steps or actions
- Connect information to my goals and objectives
## Implementation Notes
- These rules should be adjustable and evolve over time
- I should be able to prioritize which rules matter most
- The system should learn from my interactions while respecting my boundaries
- I should have full control over how these rules are appliedWhy this matters
It lets you define your context. You get to decide what information matters to you, how it’s presented, and how you’re willing to share information with a system that’s getting value from you when you search it. In effect, you’re also setting privacy boundaries.
Extend this idea and you could create a whole interface that adapts as you view different parts of the internet and receive responses. Instead of having Spotify, perhaps you have a music curation service. Instead of having YouTube, you filter available videos for the kind of thing you’re seeking.
This is almost a model-context-protocol kind of idea. I’m not sure that MCP itself will handle this sort of setup at the moment, as it has some security flaws that need to be worked out, but the basic idea is sound.
Use APIs to access content.
Apply your context to filter the content of the information you want
Get better results for yourself
The Bottom Line
The future of content isn't about using someone else's application - it's about building your own. With tools like SIFT and the rise of AI-powered development, you can create your own way to consume content. It's not about changing how companies work - it's about changing how you interact with them.
What’s the takeaway? Your context is your digital fingerprint. It's time to make it work for you, not against you. With tools like SIFT and the power to build your own applications, you can finally take control of your digital experience.
Links for Reading and Sharing
These are links that caught my 👀
1/ AI is the new pickaxes for miners - Steven Sinofsky wrote a must-read piece “From Typewriters to Transformers: AI is Just the Next Tools Abstraction” that puts AI in the context of other technological changes. The tl;dr: because AI is changing work behaviors faster than we can adapt, we will get transformational change whether we like it or not.
2/ How does this thing work? - If you want to know how LLMs like Claude work, read the System Card. Simon Willison breaks down an analysis including the things you might be worried about, like prompt injection. This answers the question: “do LLMs dream of Electric Sheep?”

3/ The value of pen and paper - Juha-Matti Santala shares how he uses a pen and a notebook as a developer to use writing and doodling as a refactoring tool. (He’s not the only one - studies have shown that switching modalities and using doodling can dramatically improve recall.)
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.
The next big thing always starts out being dismissed as a “toy.” - Chris Dixon