

The Automation-First Product Manager
PMs must evolve from design specialists to end-to-end owners who diagnose, triage, and automate their way to success. Read: "Everything Starts Out Looking Like a Toy" #264


Hi, I’m Greg 👋! I write weekly product essays, including system “handshakes”, the expectations for workflow, and the jobs to be done for data. What is Data Operations? was the first post in the series.
This week’s toy: search All Text in NYC. It’s sort of hard to describe, so start by imagining someone took Google Street Maps and made it something you can visualize by typing the name of a street or a place. Try “pencil factory.”
Edition 264 of this newsletter is here - it’s August 18, 2025.
Thanks for reading! Let me know if there’s a topic you’d like me to cover.
The Big Idea
A short long-form essay about data things
⚙️ The Full Stack Product Manager
Not long ago, the product manager role was defined by discovery and handoff. PMs interviewed customers, ran “jobs to be done” workshops, sketched flows in Figma, wrote a PRD, and then passed it to designers and engineers to bring to life.
But in 2025 (and beyond), that definition is not wrong, but it's no longer sufficient and often the cause of different team direction. You'll see teams saying "we no longer have PMs" or "our engineers vibe code the initial feature and then review" or "we design directly in figma and then hand off to linear."
These statements are jobs to be done by companies based reconciling today's reality with the original PM job description. The PM job has gotten bigger, and you need to make your own resources to scaffold the tasks that need getting done.
Today’s PMs can’t just hand off vision. When you own a feature, you’re responsible for the full stack of the customer experience — from the front-end UI to the back-end systems and operational workflows that make it real.
This shift means new expectations, new skills, and a new way of working.
Presenting the end-to-end feature owner
The Full Stack PM owns outcomes, not just specs. That means:
Understanding not only what users need, but how the system actually delivers it.
Being able to diagnose issues across UX, engineering, and operations.
Knowing when a performance regression, workflow bottleneck, or ops gap is the true root cause of a customer issue.
Where a PM once focused mostly on the PRD, now they are expected to see the entire customer journey through to delivery and operation.
Let's say you are designing a new feature to alert customers that work has been done for them by a back-end process. You always needed to consider the UI affordance (maybe a presence icon or a task toast) that would tell them there is new work done and where to find it. And in the past you definitely worked with your Engineering partner to define the user stories for the technical scope.
But now you also need to consider the edge cases in the operation that might cause that task to delay or fail. When that happens, how do you find out what's wrong? What's the mechanism that the internal ops (whether human or computer) tell the system something needs to be remediated?
Your world got bigger.
Solving the problem with diagnostics and triage
With end-to-end ownership comes new responsibilities: diagnosis and triage.
PMs need to spot patterns in Jira, dashboards, and customer feedback.
They need to make triage calls: is this a showstopper, a quick fix, or a long-term refactor?
They must know when to escalate a decision to leadership and when to pivot the team themselves.
In short: PMs are chief triage officers for their product area, blending technical understanding, customer empathy, and operational judgment.
This means you need to start thinking like a data engineer, a devops wizard, and an ops technician. With your detective eye, how would you know that something went wrong? And what is the early warning signal that you want to build into your observability system that will alert the team?
Next, once you know that there is a problem, what are you going to do to fix it? Not all problems are critical, and some need immediate action after triage. Engineers will typically define a sev 0 issue as "site down", and it's harder to quantify the impact of impaired functionality. If a UX bug happens in the app, does anyone know? And how would they know?
The PM triage framework

When you're the chief triage officer for your feature, you need a systematic approach to assess and prioritize issues.
Here's the framework:
1. Reproducibility Check
Is this a problem that happens every time, or one time?
Can you reproduce it consistently?
Does it happen in specific conditions (browser, device, user type)?
Why this matters: One-off issues often point to edge cases or data problems. Consistent issues indicate systematic problems that need immediate attention.
2. Scope Assessment
Does this affect one customer or many customers?
Is it isolated to a specific user segment or feature area?
Are there patterns in who's experiencing this?
Why this matters: Single-customer issues might be user error or edge cases. Multi-customer issues suggest systemic problems that could impact your core metrics.
3. Impact Classification
SEV0 (Critical): Broken feature that blocks core functionality
SEV1 (High): Feature works but with significant performance issues
SEV2 (Medium): Feature not performing as expected, possible UX confusion
SEV3 (Low): Suggestion or enhancement request for future consideration
Why this matters: This gives you the language to communicate urgency to engineering and leadership. It also helps you decide whether to escalate or handle it yourself.
4. Action Decision Tree
Based on your triage assessment:
SEV0/SEV1 + Reproducible + Multi-customer → Immediate escalation, engineering sprint
SEV1 + Reproducible + Single customer → Quick fix, monitor for patterns
SEV2 + Inconsistent + Multi-customer → Investigate UX patterns, consider design changes
SEV3 + One-time + Single customer → Backlog for future validation
This framework transforms vague "something's wrong" into actionable decisions that your team can execute on immediately.
Communicate your decisions widely across the land

Product managers don’t make calls in isolation. They frame decision points clearly for leadership and other teams:
"If we reinforce this initiative, Feature B will slip."
"Confidence is low — here are three options to get us back on track."
"This customer problem is more urgent than our planned roadmap item — here's the trade-off."
The PM becomes the signal amplifier in the Decision OS — translating work in Jira into decision-ready insights.
Here's the tricky thing about "insights" and "decision-ready": you need to calibrate the definition of an insight and manage the outputs so that they answer a true/false question.
"Are we ready to launch this week?" is a question an executive might ask. Behind that question is a series of conditions that must be true, managed by an observablity metric, or at least with an educated-guess hypothesis that has instructions to prove true or false after the fact.
Insights gathered from this series of inputs and true false decisions need to be consumable by business leads and business owners who want to know if their OKRs will be met, not necessarily by the details of how that will happen.
Until they do want to know more details, which is when you will use your knowledge of the inputs and their relationship to the outputs to go into detective and audit mode and produce an observability document. The goal of that document or analysis? "How did we get here, and if it's not a place we want to be, how do go somewhere else"?
Building observability into features
At its core, observability means having a condition (maybe success, maybe failure) and a way to observe it.
Here's how to build this into your user stories:
The observability user story template
Instead of just writing "As a user, I want to log in so that I can access my account," write:
As a user, I want to log in so that I can access my account. Acceptance Criteria:
Login form validates credentials
System always creates either 'success_login' or 'failed_login' event
Success redirects to dashboard, failure shows error message
Observability: Track failed_login percentage and alert when it exceeds rolling average
This creates a closed loop for your state machine:
Success path: User logs in → 'success_login' event → Dashboard loads
Failure path: User fails login → 'failed_login' event → Error shown
Monitoring: You can count % of failed_login attempts
Alerting: When failure rate spikes beyond normal, you get notified immediately
And your outcomes get crisper as well!
Before (Traditional): "User can log in successfully"
After (Observable): "User can log in successfully, and we know immediately if login success rate drops below 95%"
This transforms vague "the feature works" into measurable "we can observe the feature's health in real-time." When an executive asks, "is our login system working?" you can answer with a concrete metric instead of "I think so."
As a Full Stack PM, you're not just defining what the feature does — you're defining how you'll know it's working correctly.
This means:
Design observability into user stories from the start
Define success/failure conditions for every critical path
Create alerting thresholds that trigger before customers complain
Build dashboards that show real-time system health
This is how you move from reactive "something broke" to proactive "I can see this breaking before it affects customers."
Framing Decision-Ready Insights
The key to communicating with executives is turning observations into decision-ready insights.
Here's the framework:
The "From X to Y by when" template
A decision-ready insight presents a closed question as a statement with data, then frames the decision clearly:
"We've noticed that out of the last 500 logins, 10 have failed, and we believe that a 2% failure rate tells us we have a problem. The impact is not crushing but it's pretty annoying for that 2% of users.
I'd like us to decide whether or not to take on a story to refactor login so that we can lower this rate to 1% failure or less within the next 30 days."
Why This Framework Works
"From X to Y": States what needs to change and the magnitude (2% → 1% failure rate)
"By when": Sets clear time expectations (30 days)
Impact assessment: Quantifies the problem (annoying for 2% of users)
Decision point: Clear yes/no question for leadership
You can indicate whether a positive or negative metric is good:
"Lower is better": Failure rates, error counts, response times
"Higher is better": Success rates, completion rates, user satisfaction scores
"Target range": Some metrics have optimal ranges (e.g., 95-98% success rate)
When you don’t know yet, guess
Sometimes the problem isn't well-defined.
In those cases:
Make an educated guess based on available data
Create a structured true/false definition to test your hypothesis
Set a timeline to validate and refine your understanding
Define success criteria for when you'll know more
Example: "We suspect the login failures are related to mobile devices, but we need to investigate. I propose we spend 1 week gathering device data to confirm this hypothesis. Success means we can identify the root cause; failure means we need to investigate other factors."
This approach transforms vague "we have a problem" into structured "here's what we know, what we need to decide, and how we'll measure success."
You don't have time to do it all
The natural question: when do I have time to do this?
Answer: you don’t — unless you change how you operate.
The Full Stack PM doesn’t micromanage every Jira ticket or build every customer deck.
Instead, they:
Automate their decision weathermap — dashboards and confidence updates that surface where attention is needed.
Forecast risk early, so decisions happen before problems blow up.
Focus their analytical time on the highest-value signals.
Spend customer time where it matters most, not on every single usability detail.
It’s not about doing more work — it’s about working differently.
If you have the input bullets to create your status report, the data for your graph, and the through line for your decisions and next steps, you have all that you need.
For each artifact (launch notes, triage announcement, weekly status update, or even a graphical timeline or sequence diagram), make a new template. Tools like Cursor are amazing at helping you develop personal PM software to create your outputs from a variety of inputs.
LLMs are interns, so hire one for yourself! Tell it what to do and where to do it, and future you will thank you.
Crafting your full stack skillset
To thrive as a PM in 2025, you need to add new items to your toolkit:
Systems thinking → understanding how front-end, back-end, and ops connect.
Confidence scoring → turning Jira signals into a forecast of success, not just a % complete.
Decision framing → presenting trade-offs clearly to leadership.
Adaptive execution → knowing when to pivot, when to reinforce, and when to let go.
These skills don’t replace customer empathy or product vision — they extend them into the operating reality of today’s organizations.
Think of these as user stories for yourself:
"As a Full Stack PM, I need to be able to deliver a calibrated confidence score for a launch."
If you were writing this story as a feature, you'd come up with an MVP for how to solve it. That initial idea might be pretty rough, and then as you iterate through it and add capabilities, it would be more automatic, polished, and beautiful.
The benefit? You gain more time to think about the actual inputs to your decisions and the insights the business wants to know instead of spending your effort producing artifacts.
And when the expected format changes, update your template!
Building a maker mindset as a PM
The Full Stack PM in 2025 isn't just a facilitator. They're also a maker.
That doesn't mean coding production systems. It means vibecoding prototypes, stitching together quick demos, or building small utilities that eliminate overhead and accelerate clarity.
Prototypes → A PM should be able to spin up a quick Figma flow, a low-fidelity front-end mock, or even a working prototype to test an idea with users before design and engineering invest heavily.
Internal utilities → Instead of spending hours generating status decks, a Full Stack PM might write a small script, configure an automated Jira dashboard, or use AI tools to summarize customer feedback.
The point isn't perfection. It's speed and leverage. By building lightweight prototypes and automations, Full Stack PMs spend less time on overhead and more time answering the real questions:
What's the story the data tells us?
What decision do we need to make now?
Where should we pivot or double down?
This maker mindset makes the PM less dependent on others for early validation and less bogged down by reporting. It gives them more space to think, frame decisions, and keep the product moving forward.
If you're doing a workflow once, it's highly likely you'll do it again. So serve as your own best customer and build a portfolio of tools that improve your ability to design, build, test, and communicate.
Templates help you scale faster
For each artifact (launch notes, triage announcement, weekly status update, or even a graphical timeline or sequence diagram), make a new template.
Here are some examples you could use
The update template
- Date span
## Projects
### Project name (on track / risk / blocked / not started)
- a few bullets
## Key Actions
### This week
- [ ] todo 1
### Decisions Needed
- [ ] decision1, presented as question
The Launch Notes Template
Similar structure but focused on launch readiness:
- Launch date
## Launch Status
### Feature name (ready / needs work / blocked)
- key details
## Launch Actions
### This week
- [ ] final testing
- [ ] stakeholder approval
### Launch Decisions
- [ ] Go/no-go decision
- [ ] Rollback plan
What could you build as personal software?
I've built several tools that eliminate repetitive work:
1. Graphics Generation
Mermaid diagrams for process flows and sequence diagrams
Automated visualization of complex workflows
Template library for common PM diagrams
2. Document Processing
PDF to Markdown converter for research and documentation
Automated summarization of long documents
Template generation for common PM artifacts
3. JIRA Integration
Ticket summarization into executive summaries
Automated status updates from JIRA data
Dashboard generation for different stakeholders
4. Status Update Automation
Template-based generation from project data
Risk assessment automation based on metrics
Decision tracking and follow-up reminders
You’re building your own PM CLI
This isn't about building enterprise software. It's about creating a command line interface and context that you build with your AI intern. It's whatever you want it to be.
Examples of what you might build:
A script that takes JIRA data and outputs a status update in your preferred format
A tool that converts customer feedback into structured insights
An automation that generates Mermaid diagrams from your process descriptions
A dashboard that shows your key metrics in one place
The goal is to eliminate the 80% of repetitive work that doesn't require human judgment, so you can focus on the 20% that does: making decisions, understanding customers, and driving strategy.
Start small. Build one template. Automate one repetitive task. Then build another. Before you know it, you'll have a personal PM toolkit that makes you 10x more effective.
Full stack is the new default
The PM job isn’t getting smaller. It’s getting bigger. But it’s also getting smarter.
The Full Stack Product Manager doesn’t just discover problems and write specs. They run the decision system that keeps strategy alive.
In 2025, being “full stack” means:
Seeing across design, engineering, and ops.
Diagnosing and triaging with clarity.
Communicating decision points and trade-offs.
Prototyping and automating to free up time.
Protecting IC focus while giving execs visibility.
This isn’t the PM role of 2015 or 2020. It’s the PM role of today — and tomorrow.
Start your action plan today
The actionable next step is simple: decide one thing today that you are going to automate.
Step 1: Choose your first automation
Pick something repetitive that takes you 30+ minutes each week:
Weekly status report generation
Customer feedback summarization
Meeting note templates
Dashboard updates
Any repetitive PM task
Step 2: Have a conversation with an LLM
Talk to an LLM about how it would instruct a developer or agent to build your automation:
Describe your current process in detail
Ask for a technical approach to automate it
Get specific about inputs/outputs and edge cases
Discuss the user experience you want
This conversation helps you think like a product manager for your own tools.
Step 3: Build with Cursor or Claude
Use that LLM conversation to start building with Cursor or Claude:
Break down the problem into smaller pieces
Start with a simple prototype that works for one case
Iterate and improve based on what you learn
Make it reusable from the beginning
Step 4: Think like a product manager
As you build your first utility, think about:
Reusability: How can this solve similar problems?
Utilities needed: What supporting tools would make this easier?
Debugging: How will you troubleshoot when it breaks?
User experience: How will you and others use this tool?
This is a great product exercise that will help you:
Talk to engineers more effectively about requirements
Communicate with stakeholders about technical trade-offs
Understand the development process from the inside
Build better products by experiencing the builder's perspective
Start small, think BIG
Your first automation might be simple, but it will teach you:
How to break down problems into buildable pieces
What questions to ask when defining requirements
How to iterate and improve based on usage
The satisfaction of building something that makes your life easier
Today's action: Pick one thing to automate. Have that LLM conversation. Start building. You'll be amazed at how quickly you develop your maker mindset and how much more effective you become as a PM.
The Full Stack PM isn't just a role — it's a mindset. And that mindset starts with one simple decision: to build instead of just manage.
What’s the takeaway? You might want to spend your time in only one of these modes of working, and today's businesses demand that you handle all of them. So build your personal toolkit to emphasize your strengths and shore up your weaknesses, and future you will appreciate it!
Links for Reading and Sharing
These are links that caught my 👀
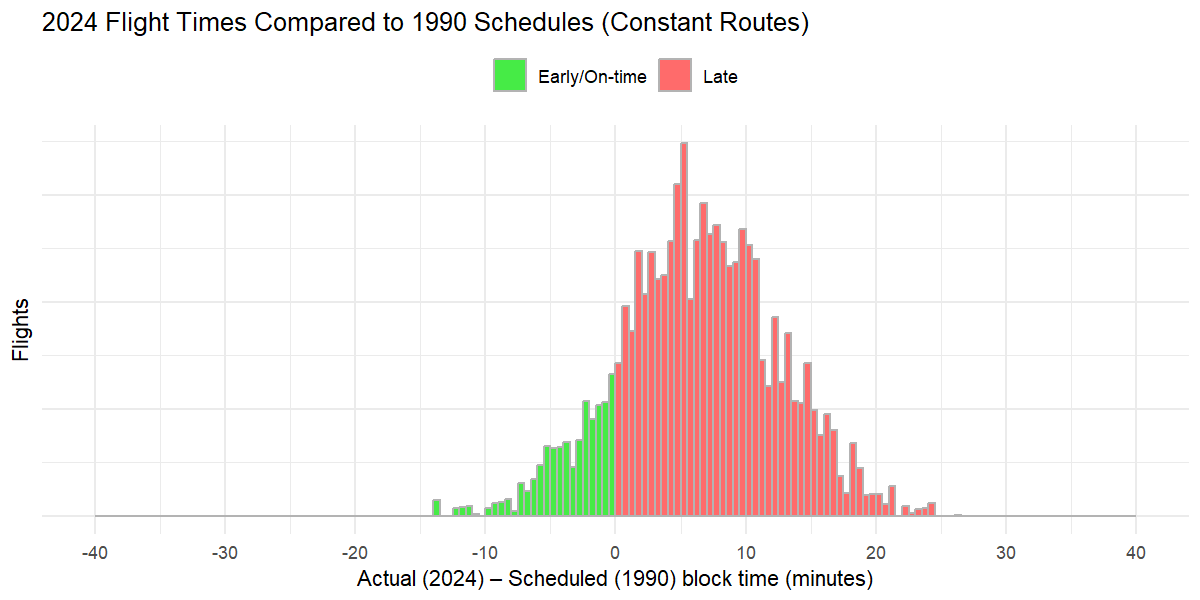
1/ It’s not your imagination - Flight delays are getting more prevalent, and worse. It’s not just because airlines have changed the time it takes to fly somewhere to make more flights “on time.”
2/ What can I build? - In a world where you *could* build anything, what would you build? Here are some examples of apps people have built to solve their everyday issues. Like every good PM, start with the end in mind. What pain are you solving? If there is no obvious pain, ask: why are we building?
3/ Doing v. Delegating - As you progress in an org, you need to do both. The challenge? It may feel like you are delaying the doing if you stop to think about how to find the critical path to solve the issue. Delegating may be faster than doing, but you need to provide the key insights, order of operations, and decision points where you’ll need to weigh in.
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.
The next big thing always starts out being dismissed as a “toy.” - Chris Dixon