

The Three Minute AI Skill Test
Want to get better results from AI? Three minutes turn AI prompts into repeatable skills. Read: “Everything Starts Out Looking Like a Toy" #293

Hi, I’m Greg 👋! I write weekly product essays, including system “handshakes”, the expectations for workflow, and the jobs to be done for data. What is Data Operations? was the first post in the series.
This week’s toy: a 1983 adventure game made “new” by Claude. Maybe old dogs can do new tricks!
Edition 293 of this newsletter is here - it’s February 23, 2026.
Thanks for reading! Let me know if there’s a topic you’d like me to cover.
The Big Idea
A short long-form essay about data things
⚙️ The Three Minute AI Skill Test
The first time I used a large language model, it felt like cheating.
I dropped in messy notes and got back a cleaner argument than I could have written in one pass. It surfaced connections I had not named yet. It made rough thinking look polished.
The second time I tried to reproduce that result, the magic disappeared.
Same tool. Similar prompt. Worse output.
That is where most teams get stuck. They mistake first-pass surprise for capability.
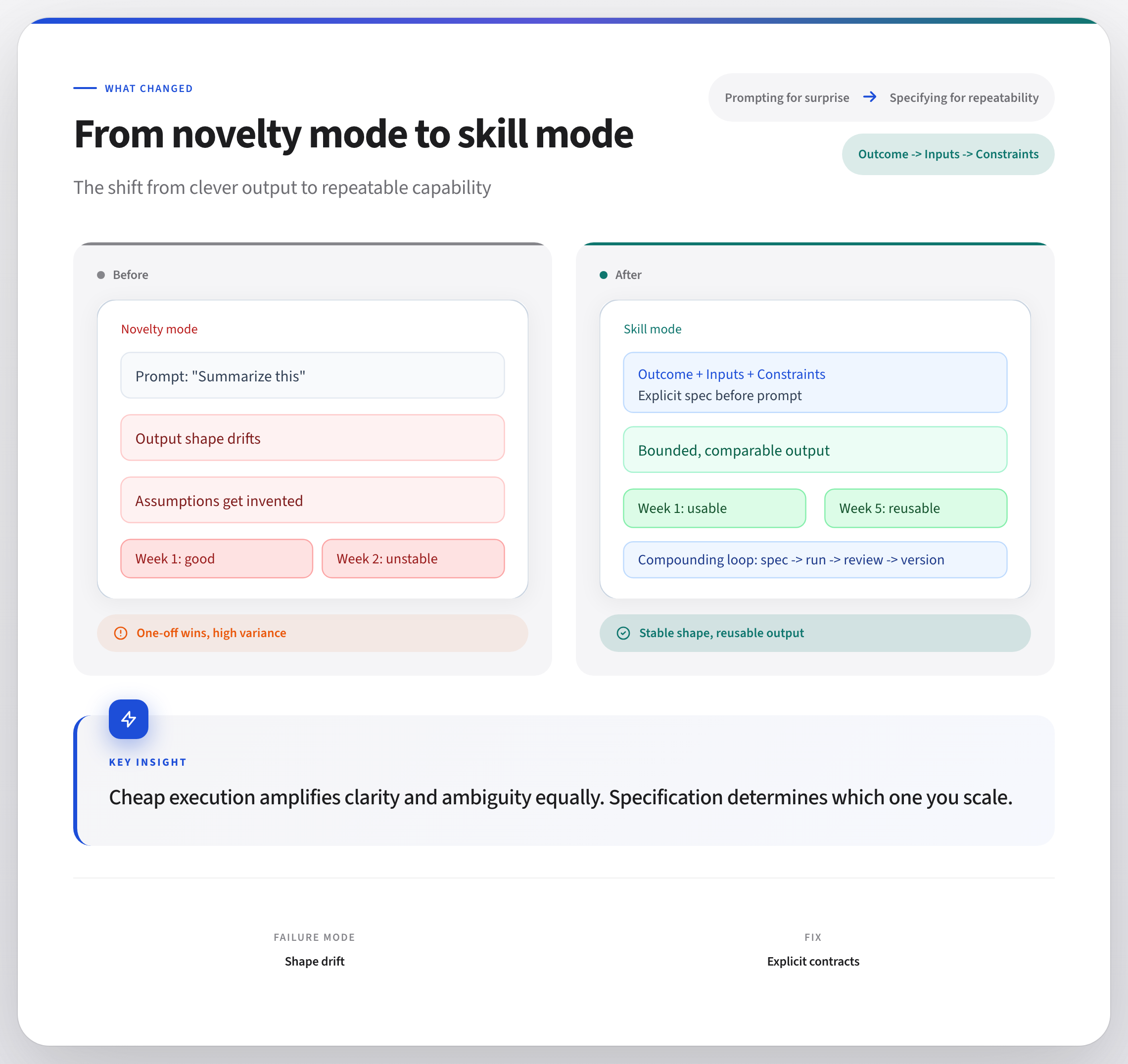
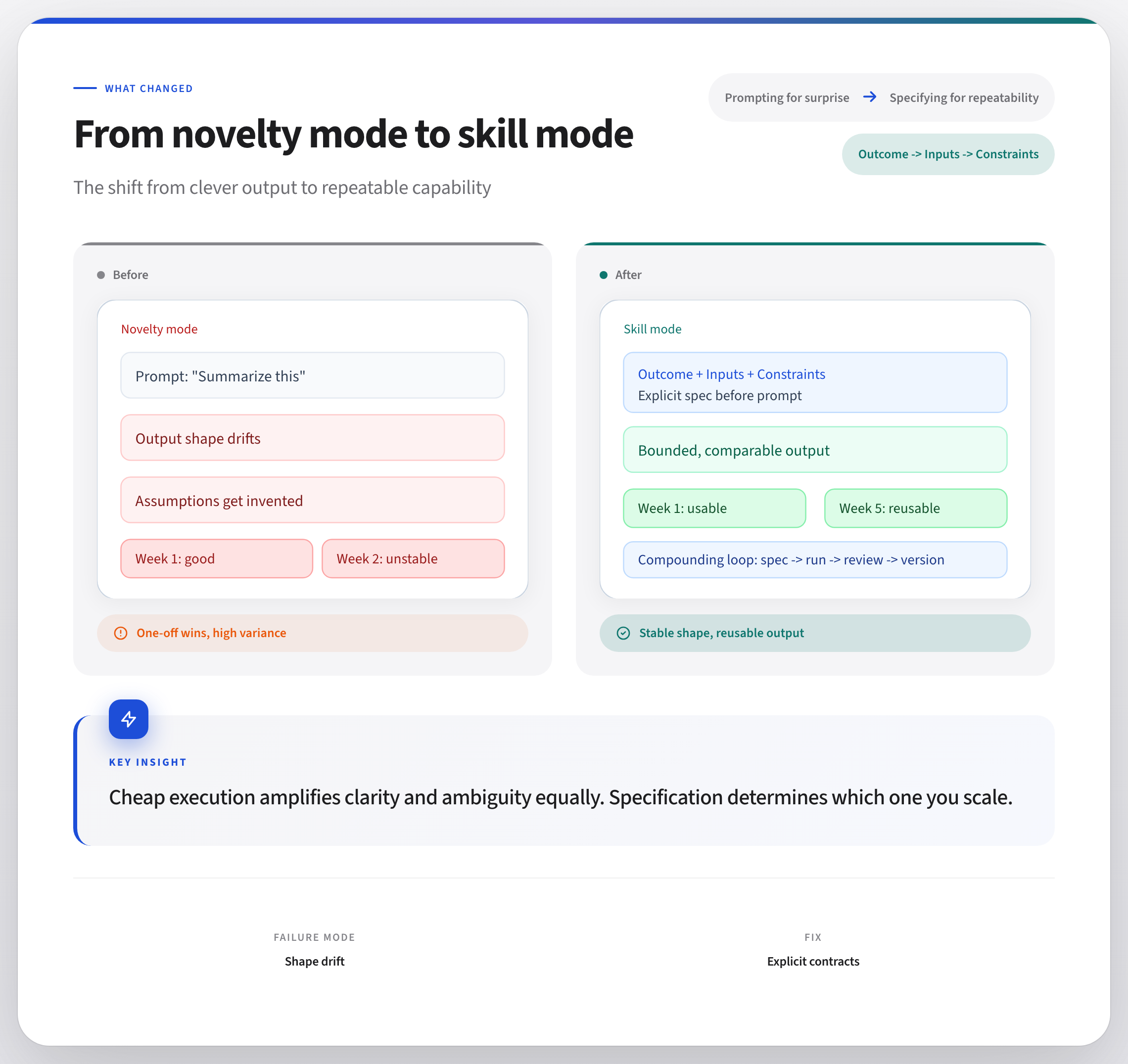
If you want AI work to compound, run a three-minute check before you open chat:
Outcome: What exact shape should the answer take?
Inputs: What specific material will I provide?
Constraints: What must it not assume, exceed, or invent?
That pause looks trivial. It is not.
It is the difference between a clever prompt and a repeatable skill.
The bottleneck already moved
Most teams still think the hard part is generating output. That used to be true.
Today, generation is cheap. You can create drafts, summaries, and analysis in seconds. The bottleneck is no longer typing speed. The bottleneck is specification quality.
When your specification is vague, AI fills gaps with plausible noise. When your specification is sharp, AI gives you structured leverage.
Cheap execution amplifies both.
This is why many teams report the same experience:
They get one strong result.
They cannot reproduce it next week.
They conclude the model is inconsistent.
In most cases, the inconsistency is upstream, and results from them not being specific (to be terrific, you must be specific!)
Novelty mode vs skill mode
In novelty mode, you paste content into a chat and see what happens. (Vibe coding ftw!) If the output sounds smart, you keep it. If not, you nudge wording and try again.
Novelty mode is useful for exploration, but it’s not good for building repeatable operations.
In skill mode, you define the result class first, then prompt.
You are not asking for “a summary.” You are asking for “five bullets: one risk, one tradeoff, one open dependency, one owner question, one decision recommendation.”
You are not asking for “feedback.” You are asking for “critique against these criteria, with evidence quoted from the source, no external assumptions.”
Skill mode creates bounded variation: output changes based on inputs, but stays in the same useful shape.
That is what teams can reuse.
A concrete micro-story
A product operations team I worked with had a weekly ticket triage ritual. Every Friday, one PM spent two hours reading support tickets and writing a Monday brief for engineering and CX.
Imagine this experience and how it would work today with AI. You might be able to vibe code this in an afternoon, and the outcome will look great. Celebrations all around!
Week two might not look the same as your initial success. Some summaries are long and fluffy, and others invent implied causes that were never in the ticket text. When you get the blank stare from your team members and can only respond, “I’ll have to look into why the robot did that,” it’s not a reply you can repeat often before you lose trust with the team.
Instead, what if your new process looks like this? Before the report, they use the three-minute test before each run:
Outcome: “Return exactly eight bullets grouped by issue cluster, each with count and one user quote.”
Inputs: “This CSV plus last week’s cluster labels.”
Constraints: “No root-cause claims. No recommendations. Only evidence in provided text.”
Quality stabilizes immediately. Review time falls from two hours to twenty-five minutes. More importantly, outputs are comparable week to week.
This team is not discovering a better model. They are simply describing their problem consistently and building a scalable insight pipeline.
Outcome, Inputs, Constraints in practice

Why does this work, and where should you be skeptical of this method?
Each line in the test solves a specific failure mode.
1) Outcome prevents shape drift
Without an explicit outcome, a model chooses its own format, depth, and emphasis. That may look impressive once, then break downstream.
Define structure up front: length, sections, ordering, mandatory fields.
If another teammate can recognize the same output class in ten seconds, your outcome is clear enough.
2) Inputs prevent hidden scaffolding
Most bad outputs come from missing context the model guessed at.
Be literal about source boundaries:
Which documents are in scope?
Which are excluded?
Which fields are authoritative?
This reduces hallucinated glue logic and keeps traceability intact.
3) Constraints prevent confident fiction
Constraints are not bureaucracy. They are portability.
Set explicit guardrails for assumptions, tone, evidence, and length. If you do not, models optimize for fluency over fidelity.
Good constraints make output safe to reuse across teammates and weeks.
From prompting to operating model
A prompt is a one-time instruction. A skill is a repeatable capability with boundaries that can be made for your local use (in Claude, ChatGPT, or Gemini), generalized for any problem you build in those tools, or made into a skill.md file that you can share with others.
When building a skill, use a compact six-step loop:
Name the recurring job: what repeats weekly or daily?
Lock output shape: what exact artifact is needed?
Lock input contract: what source set is always provided?
Lock constraints: what assumptions are forbidden?
Run and score: what failed against spec?
Version the pattern: what changed and why?
If the workflow survives the fifth use with a different teammate, you are building capability that goes beyond you!
If it only works when the original author babysits prompts, you are collecting tricks. (Which are sometimes still awesome, but less useful outside of a narrow use case.)
Light mechanics for agent-era teams
As teams add more automation, this gets even more important.
A skill can encode the expected output contract. A scoped subagent can run a bounded task in parallel. A lightweight PR gate can check whether output met the declared structure and constraints.
None of that replaces judgment. It operationalizes clarity.
You do not need a heavy platform to start. Even a markdown template with Outcome, Inputs, Constraints before each recurring AI task is enough to change behavior.
The capability challenge for PMs and leads
The uncomfortable truth is that execution acceleration raises the bar for decision quality.
When teams can generate many plausible options quickly, approving work becomes the high-leverage act.
Leaders who reward “more output” without stronger specification standards will get volume without compounding.
The better posture is simple:
Ask teams to show the output contract before the prompt.
Reject results that are eloquent but non-compliant with constraints.
Track reproducibility, not just first-pass quality.
This is a learnable muscle, not a talent lottery.

What’s the takeaway? If you want to know whether your team is building AI capability or just collecting clever prompts, run the Three Minute AI Skill Test before the next recurring task. The leverage is not in typing faster. The leverage is in the pause that defines the work.
Links for Reading and Sharing
These are links that caught my 👀
1/ Making software to last? - creating durable software feels strange in a world where you can ask a bot to build things. Dan Hock posits a way through this is to focus on the benefit. (Classic advice.)
2/ how to avoid hallucinations - What to worry about when you’re searching with AI? I’d say you need to know how the system retrieves and validates information.
3/ a portrait of an artist - Claude draws a self-portrait with a plotter. If nothing else, this is a fascinating art project.
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.
The next big thing always starts out being dismissed as a “toy.” - Chris Dixon