

When you need an incremental data metric for your report, the rollup is your friend
Let's talk about a common problem with data & analytics. How do you make it easier to add incremental related fields to a report? Read: "Everything Starts Out Looking Like a Toy" #150
Hi, I’m Greg 👋! I write weekly product essays, including system “handshakes”, the expectations for workflow, and the jobs to be done for data. What is Data Operations? is a post that grew into Data & Ops, a team to help you with product, data, and operations.
This week’s toy: an a/r tool of sorts - it’s a “camera” that captures information and builds a generative picture based on the various data points captured by this device. See for yourself - this is both a hallucination and a reasonable facsimile of a time and place. It’s not a photograph, but it’s something more than just a prompt and connects physical data to generative AI.
Edition 150 of this newsletter is here - it’s June 20, 2023.

Brought to you by Pocus, a Revenue Data Platform built for go-to-market teams to analyze, visualize, and action data about their prospects and customers without needing engineers. Pocus helps companies like Miro, Webflow, Loom, and Superhuman save 10+ hours/week digging through data to surface millions in new revenue opportunities.
If you're reading and haven't subscribed (yet), give it a try! And if you have any comments or are interested in sponsoring, hit reply.
The Big Idea
A short long-form essay about data things
⚙️ When you need an incremental data metric for your report, the rollup is your friend

Data engineers or report writers, has this happened to you recently?
You are querying a table to build a report, and you get an additional requirement from a stakeholder for one more thing.
“Can you add the count of (sales, users, something) per account to this report?”
In many business intelligence tools, adding this relatively simple count turns out to be a harder problem than you would expect.
When you join the additional table to the data set and group by the key (let’s say the account), you’ll get all of the rows in the set. This means that if you are getting sales data by account it’s not that hard to get a count of the number of closed won sales.
What can be challenging is adding that “roll-up” field – called a roll-up because it is counting an aggregate for a key like accountID – to a report that contains other fields that you don’t want to group.
Grouping typically creates too much information
In most business intelligence tools, a grouping action forces you to have extra rows or to view only the aggregate information along with the main key.
Take this example from a Salesforce development environment. When you sum the opportunity count by account, you see the record count by account.
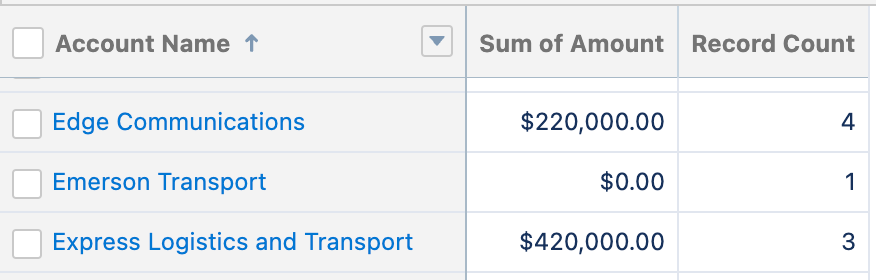
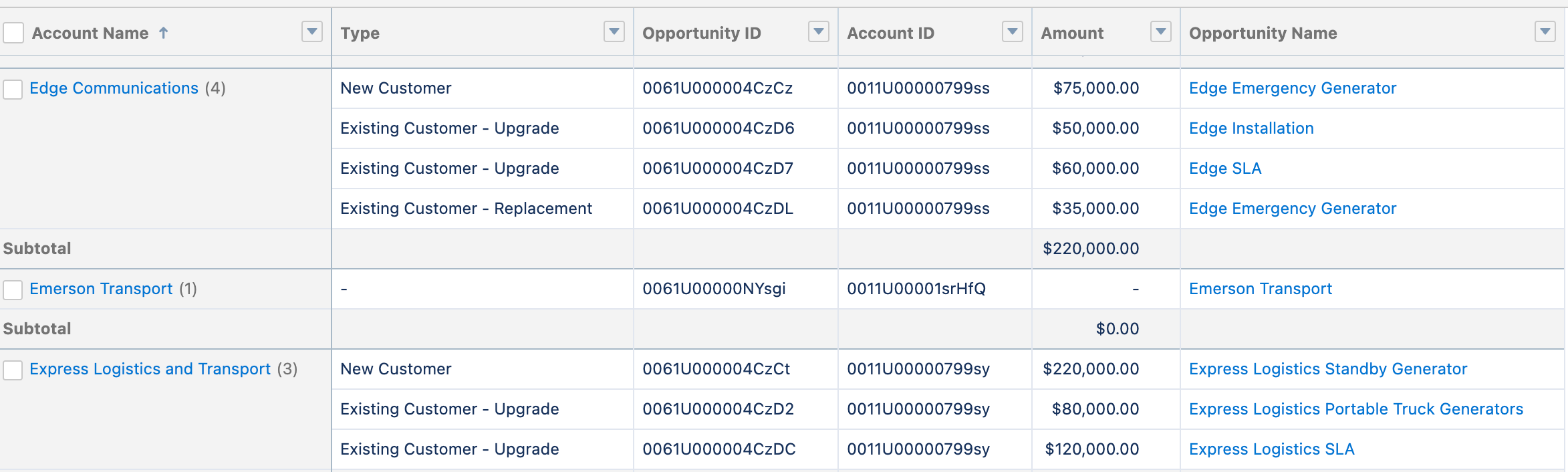
When you add an additional field to your group, it’s possible to make a new aggregate, summing the records in your expanded group.

But when you want to add ungrouped fields, you get more rows. This makes sense and is typical for the way that databases work.
The challenge happens when your stakeholder would like you to add another piece of information – for example, counting the number of engaged or product-qualified contacts at each account.
Answering this other question requires another report that uses the same shared key (the account ID) to find the number of engaged contacts for each account based on some criteria. The output is a single number, along with the same unique key you used in the first report.
Now, you’d like to union these two reports so that the field you looked up in report two (the number of engaged contacts) can easily be added to the first report (counting the number of opportunities) for each account.
It turns out this is not an easy thing to do.
Salesforce makes this possible by creating a joined report, which solves part of the problem. You can see the joined data, but it’s not easy to export it in an easy-to-use format.
If you know the key of a related record, why can’t you just append a field to your dataset?
BI tools don’t expect linked questions (but should)
In a perfect world, you would expect to be able to define a roll-up as a related metric on each object. In this case, the object is the account and the rolled-up information consists of attributes that you calculate independently for each account and then can add as a field.
In the Salesforce universe, many people use Rollup helper, a free tool that periodically calculates these metrics for the objects you specify:
e.g. a skinny table with the account ID and the opportunityID, amount, close date, and stage
Then you have the current YTD sales for that company and can add it to a company record
Rollup helper runs this query as a background item and populates a field in your object (the account, for example) so that you can reference the output of the roll-up query as an inline field rather than a set of rows that you add up.
In other BI tools like Sigma, you can write a query directly in SQL and then use it as the input for another report, using the key in that query as join criteria.
This is a great approach because instead of the messy grouped report we looked at above, you can simply add one more field to your dataset. Within reason, you can keep grouping adjacent datasets that have the same account ID.
I know DBAs everywhere are rolling their eyes at me. 👀
Schema design informed by ad-hoc queries is not the way databases should be designed or built. 🤷
But if you put your product hat on, you’ll see that this is a very common use case for users who need to add “just one more field” to their reports.
⭐️ Making this use case possible (and even delightful) is a worthy goal. ⭐️
What would it look like to anticipate linked metrics?
The way that Sigma approaches this problem is a pretty solid model:
Lets you write a query against known data, essentially creating a mini-model
Determine how often this should run (ideally, as a view that can provide instant information as you run other reports)
Name and save this dataset as a structure you can union against other data in your environment by specifying the join type and join field
What if we were to build a roll-up feature to offer more capability to a business intelligence tool?
We would want this to feel basically the same as the effort required to add a tab to your spreadsheet with new information, designate one column to be the unique (and related) key, and suggest potential roll-up combinations.
I would expect this feature to do the following:
based on the unique key for the current base report, suggest reports that group information using that same unique key
if there are secondary unique keys also present in that base report, optionally suggest groupings for those keys too
allow you to add one of these external groupings at a time
if the combined grouping is invalid, warn me that it results in too many or not enough records
To support this, you’d need a way to bucket these queries to be related based on the key, run them periodically to know if they are in an error state, and keep track of how often they are used or joined to other queries.
A bonus: snapshots of changing data
One of the side benefits of checking queries on a schedule and validating that they still work is the ability to create a “snapshot”, or a stored view of the report at a certain period in time.
For example, you might want to run your “active user count” report every week and stamp that result with the date of your combined report. Salesforce makes this capability available with snapshots so that you can build a time series for changing data.
But what if you don’t use Salesforce? There’s an interesting niche here to run reports on a schedule and store these generated reports using a common schema and then be able to visualize changes over time.
You could also use these past reports for analysis, unioning additional datasets on these historical reports for analysis. This is an example where Sigma Computing shines.
What’s the takeaway? Roll-up fields add a very useful dimension to existing reporting and enable you to create deeper analysis and filtering. By creating “skinny tables” of information you can join on a unique key, you make it possible to answer almost every “just one more thing” question your stakeholders ask about a dataset.
Links for Reading and Sharing
These are links that caught my 👀
1/ Hello world for Data Product - As a data ops professional, it might not feel that you are close to making data work more like a product in your org. This essay on productizing data is a master class in moving to a data product-oriented process. Put simply, most operational departments don’t create a vision, demonstrate progress on a visible road map, and have a criteria to accelerate or decelerate work based on agreed-upon goals (kind of like a product road map).
2/ What’s the best way to measure product analytics - I like this explanation of 3 steps to effective product analytics because the goals of data quality, exploratory analysis and self-service will unlock the data exploration from the data wizards themselves. With these principles in place, it will be a lot easier for business users to answer data questions and for data teams to feel that the GTM team is building reports that have reasonable and congruent answers.
3/ Need a metrics benchmark? - the team at Insight Partners surveyed hundreds of companies and produced their latest example of Saas metric benchmarks. Using this report, you can get some feedback and comparison to other companies, segmented by stage.
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.
Want to book a discovery call to talk about how we can work together?
The next big thing always starts out being dismissed as a “toy.” - Chris Dixon