

How many AI Agents can one human manage?
Your next job is managing agents, and the limit isn't their intelligence, but span of control. One human can only steer so many agents. Read: "Everything starts looking like a toy" #305


Hi, I’m Greg 👋! I write weekly product essays, including system “handshakes”, the expectations for workflow, and the jobs to be done for data. What is Data Operations? was the first post in the series.
This week’s toy: a video effect that makes your new videos look like old one - the VHS effect. Add some visual interference (what we used to call “snow” when the analog picture reception was lousy) and you’ll be ready for the next Poltergeist remake.
Edition 305 of this newsletter is here - it’s June 29, 2026.
Thanks for reading! Let me know if there’s a topic you’d like me to cover.
The Big Idea
A short long-form essay about data things
⚙️ How many AI Agents can one human manage?

On a Toyota assembly line, there’s a cord that runs the length of the floor, and any worker can pull it.
Pull it and the line stops. Not your station, but the whole line. It sounds reckless, like handing every worker a kill switch for the factory, and your first instinct is that it can’t possibly scale.
But the Andon cord is the opposite of reckless. It’s the most considered part of the system. Toyota decided that the cheapest place to catch a defect is the moment a human notices it, so they built the line to put human judgment exactly there, in the hands of the person closest to the problem. The whole thing is designed around the assumption that a person will stop it.
There’s a second thing baked into that design, and it’s the one nobody talks about. The line only works because each worker can actually watch their stretch of it. Give one person too much line, too many stations, too many things to notice at once, and the cord stops meaning anything. They can’t see the defect, so they can’t pull the cord, so the whole safety model quietly fails.
That second thing is the job that’s coming for you.
Your next coworker doesn’t have a face
You already know agents are going to land in your workflows. We’ve covered how to introduce them into operations before. The interesting question now isn’t whether they’re good enough. It’s what it means to manage them.
Because that’s the actual job title forming under your feet: not doing the work, but supervising a set of agents who do it, and stepping in when they can’t.
And the constraint on that job is not how smart the agents are. It’s how many of them one human can steer before that human becomes the bottleneck. Factory managers have a name for this: span of control. How many people can one manager actually manage? With agents, the question is the same, except your reports never sleep, they ask questions at three in the morning, and some of them are confidently wrong.
So the real question of the next few years isn’t “can the agent do it.” It’s “how many can you hold.”
What the human in the loop actually does

Strip away the mystique and the job is concrete. When an agent is running and you’re the human in the loop, you get asked to do a handful of things, over and over:
Redirect an agent when it fails or wanders off the path.
Answer a question it can’t resolve on its own.
Define the outcome when you’re the one who knows what “done” means.
Break a tie when two paths look equally good and only judgment separates them.
Underneath all four is the same thing. You supply the judgment the system can’t generate for itself. The agent can execute, search, draft, and retry all day. What it cannot do is decide what should happen when the situation is genuinely ambiguous — and the more capable agents get, the more that ambiguity is the only thing left on your desk.
This is the same muscle I wrote about in grading what your machines make — being the one who tells a sound call from a confident fabrication. Span of control is what happens when you have to do that grading across ten machines at once instead of one.
The ratio is set by the quality of the questions
Here’s the lever, and it’s not the one people reach for first.
Most people try to raise their span of control by becoming a better, faster grader. That helps a little. But the bigger lever is upstream: how good the agent is at knowing when to ask.
A well-designed agent comes with a plan, a clear sense of its outcomes, the tools to do its work, and — this is the part that’s easy to skip — explicit conditions for when to interrupt and pull you in. It should know how to wait, how to escalate, and how to go to sleep when its job is actually done. (That design work is its own subject; I’ve written about building agents that escalate well, and about the inbox where those questions should land instead of a chat window you’ll never see again.)
Get that design right and the questions you get are few and sharp. Each one has a real answer and arrives with enough context to answer it in seconds. Get it wrong and you drown, resulting in vague questions, missing context, and the same issue three times because nobody taught the agent what “resolved” looks like.
Fewer, sharper questions per agent means more agents per human. That’s the whole equation. Your span of control isn’t a fixed number you were born with. It’s a function of how well the loop is built.
When the ratio holds
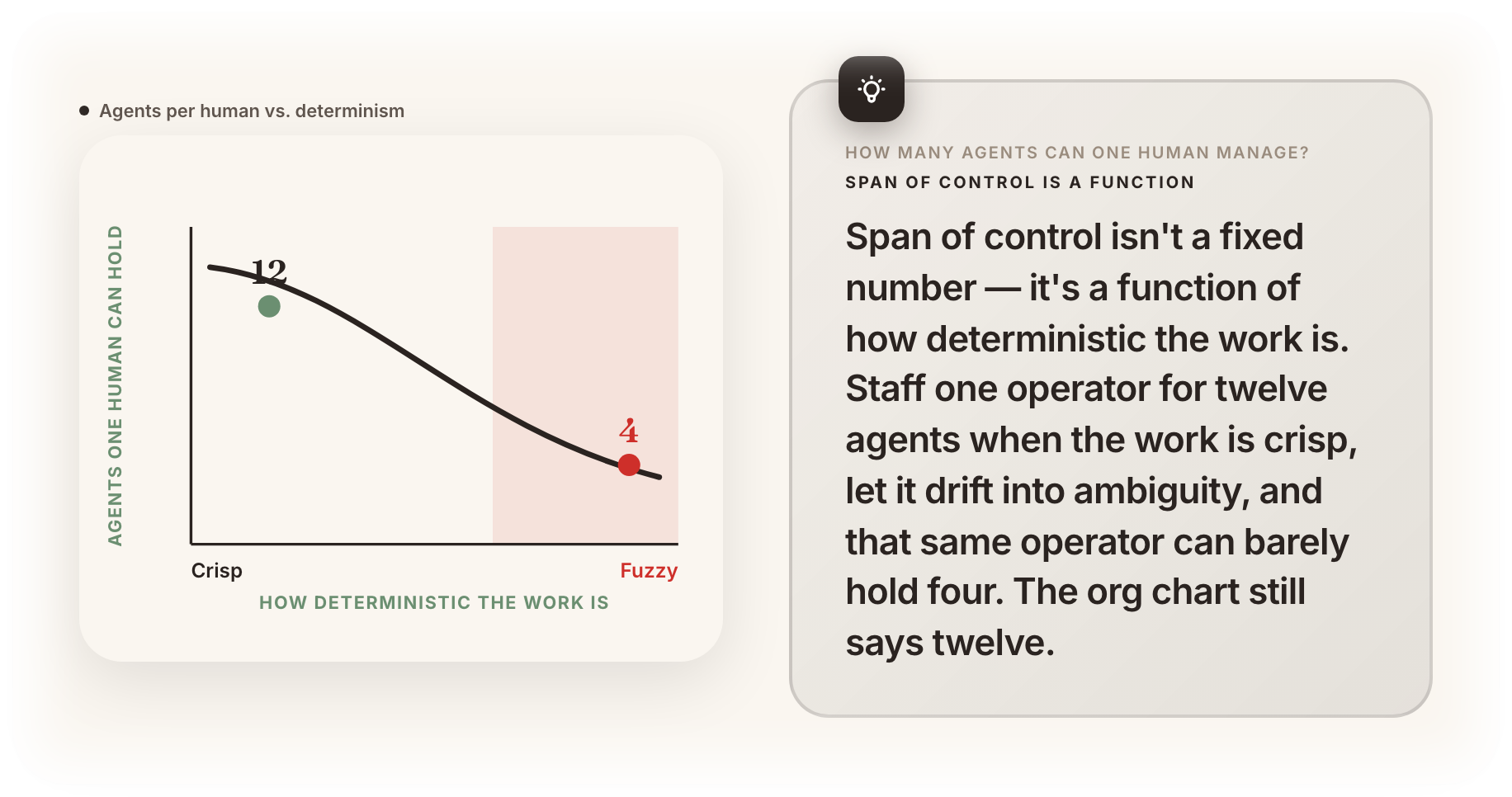
There’s a set of conditions where one human comfortably runs a crowd of agents. You can feel it when it’s working:
The number of agents is manageable — you’re not getting pinged faster than you can think. The questions have right answers, so your judgment converges instead of spinning. Deadlines get met and quality stays consistent, which means you can trust the parts you’re not watching. And the outcomes are deterministic enough that “done” means the same thing every time.
When those hold, the cord works. You can watch your stretch of line. You catch the defects. The ratio is high and steady, and adding one more agent doesn’t break you.
When the ratio collapses
Now flip each one, because this is where teams actually get hurt.
Too many agents, and you can’t see any single stretch of line clearly. Non-deterministic questions are fuzzy, context-dependent, with no clean answer, and every one costs real thought instead of a reflex. When you aren’t sure, deadlines slip, so the things you weren’t watching turn out to be on fire. When you have outcomes that aren’t deterministic, “done” is a judgment call too, on top of all the others.
The trap is that span of control isn’t a cliff you see coming. The number of agents one human can hold drops as the questions get fuzzier, and it drops fast. You staffed one operator for twelve agents back when the work was crisp, and now the work has drifted into ambiguity and that same operator can barely hold four — but the org chart still says twelve. Nobody pulled a cord, because nobody could see the line anymore.
So the most important number on an agent team isn’t how many agents you have. It’s how many your humans can actually supervise given how deterministic the work is — and that second number moves.
Pull the cord
Which brings us back to the floor.
Even a well-run loop hits moments where the priority changes from outside the agent’s view. A customer escalates. A regulation shifts. The thing that was routine this morning is now the only thing that matters, and no agent in the system has any way to know that, because the signal lives outside what any of them can see.

That’s the moment you need an Andon cord. A deliberate way for a human to stop the line, re-rank the work, and decide what the agents do while everything’s paused — wait, hold, or fall back to a safe default. You have to decide in advance who’s allowed to pull it and what counts as a good reason, the same way Toyota didn’t leave “should I stop the line” to a debate in the moment.
The cord is also where smarter agents buy back your span of control. An agent that runs a real OODA loop — observe, orient, decide, act — before it interrupts you is an agent that resolves more on its own and pulls you in only when it should. Every question it handles itself is a question you don’t have to. That’s the difference between holding four agents and holding fourteen.
The bottleneck was never whether the agents are smart enough. It’s how much human judgment you can supply per unit of time, and how well the loop spends it.
Skip them, and you’ll hire a roomful of brilliant agents, point them at the work, and watch one tired person in the middle quietly become the thing that breaks.
What’s the takeaway? Your job is to raise your span of control on purpose. Build agents that ask fewer, sharper questions. Push the work toward outcomes that are deterministic enough to trust. Decide who pulls the cord, and when. Do those, and one human can stand over a surprising amount of line.
Links for Reading and Sharing
These are links that caught my 👀
1/ How to judge agents - If you don’t already know how to build Evals - the “judges” that help us know whether an Agent is doing a good or bad job - it’s time to learn. The output needs to be deterministic (either by running code or hiring another LLM to judge).
2/ Is everyone using AI? - No, not yet. If you’re reading this you’re probably ahead of the curve.
3/ Colors - A great compendium of colors. Go ahead and find your favorites!
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.